Stepwise Credit Assignment for GRPO on Flow-Matching Models
*Work done while intern at Adobe
Abstract
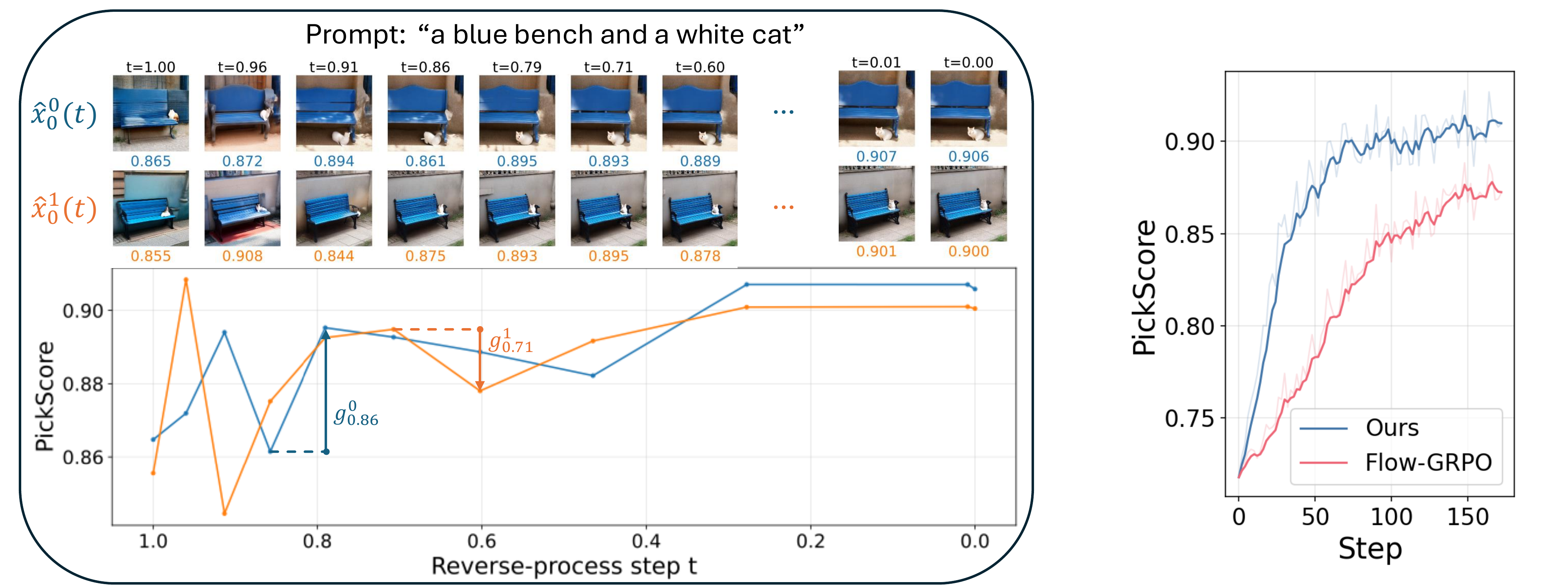
Flow-GRPO successfully applies reinforcement learning to flow models, but uses uniform credit assignment across all steps. This ignores the temporal structure of diffusion generation: early steps determine composition and content (low-frequency structure), while late steps resolve details and textures (high-frequency details). Moreover, assigning uniform credit based solely on the final image can inadvertently reward suboptimal intermediate steps, especially when errors are corrected later in the diffusion trajectory. We propose Stepwise-Flow-GRPO, which assigns credit based on each step's reward improvement. By leveraging Tweedie's formula to obtain intermediate reward estimates and introducing gain-based advantages, our method achieves superior sample efficiency and faster convergence. We also introduce a DDIM-inspired SDE that improves reward quality while preserving stochasticity for policy gradients.
Key Results
(vs 0.72 Flow-GRPO)
sample & wall-clock efficiency
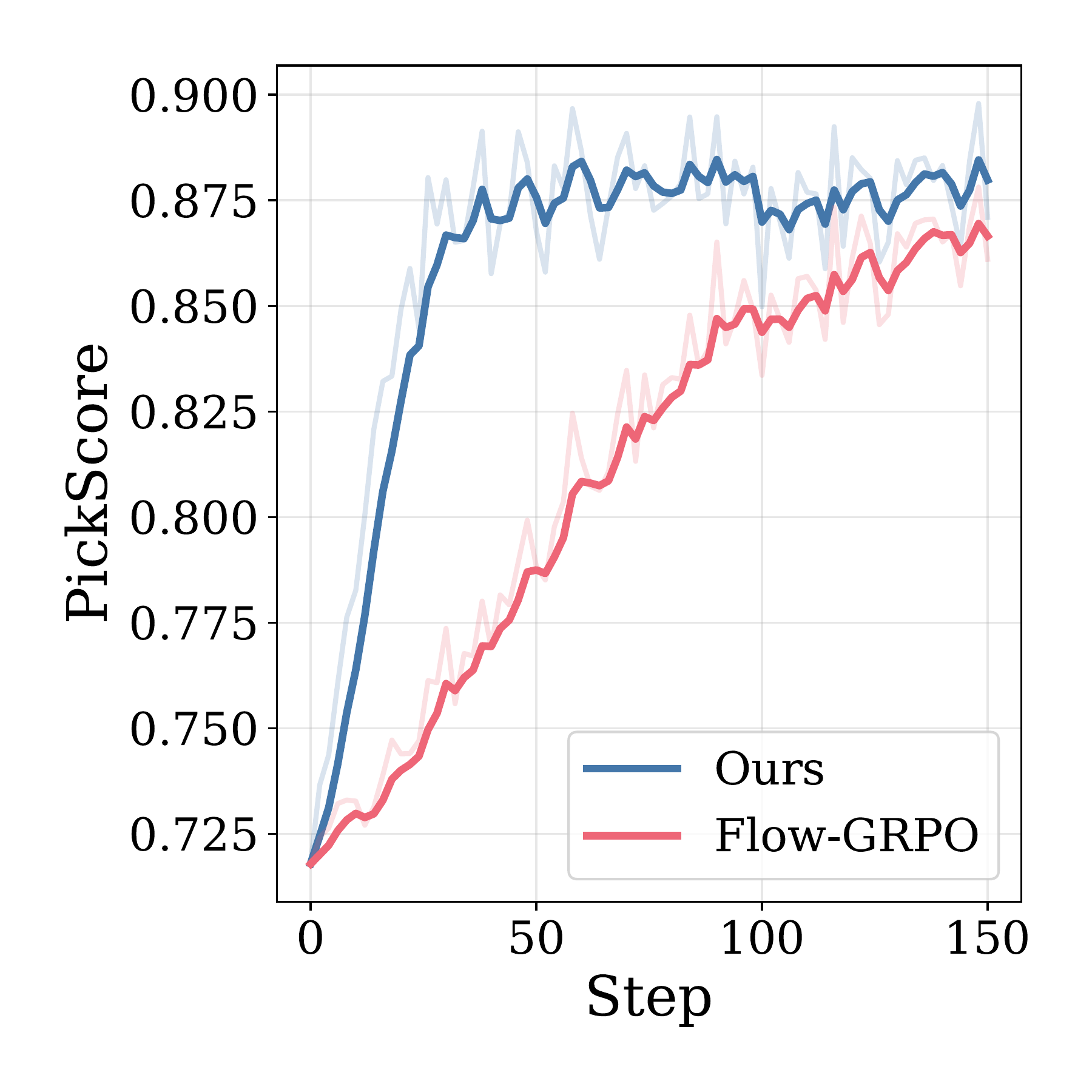
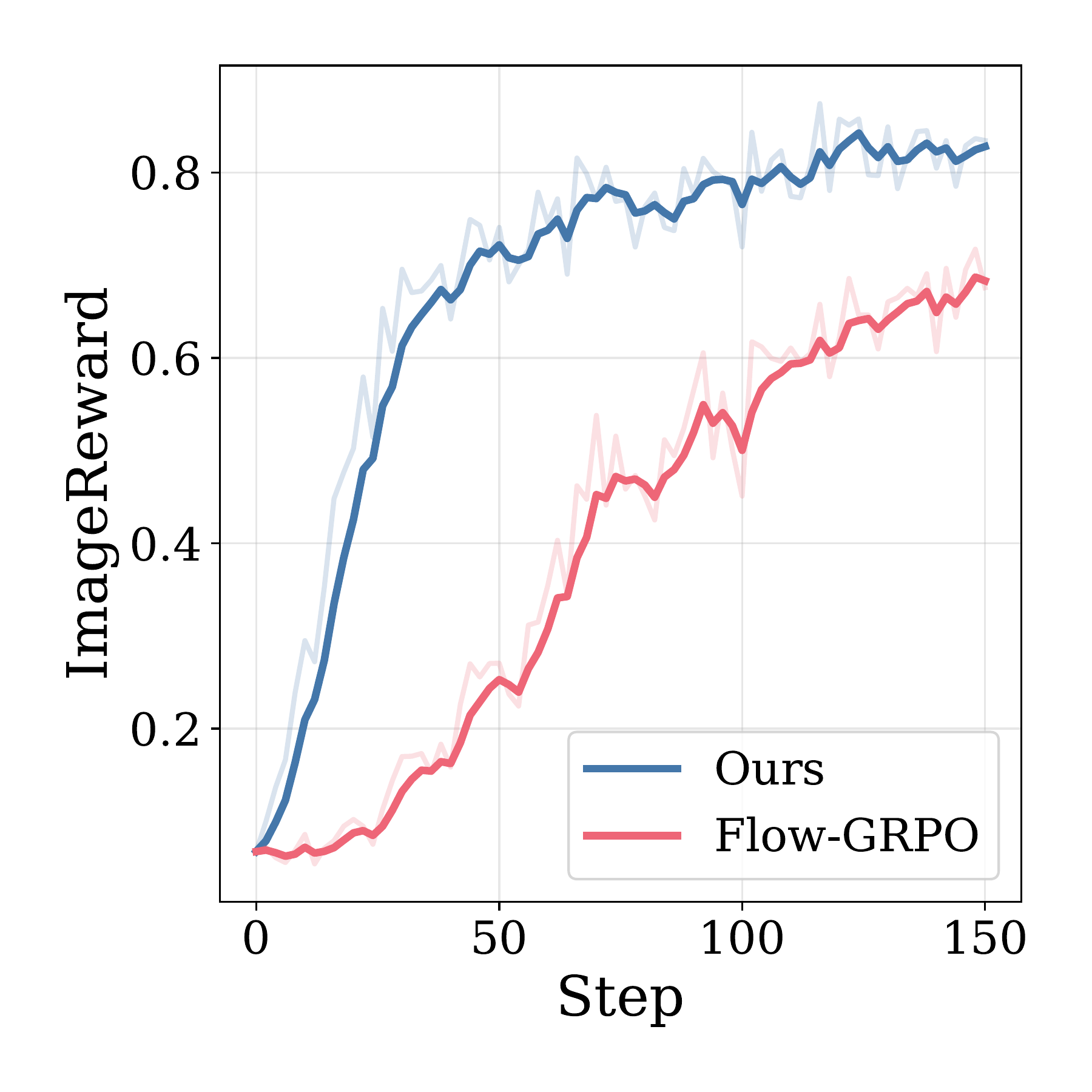
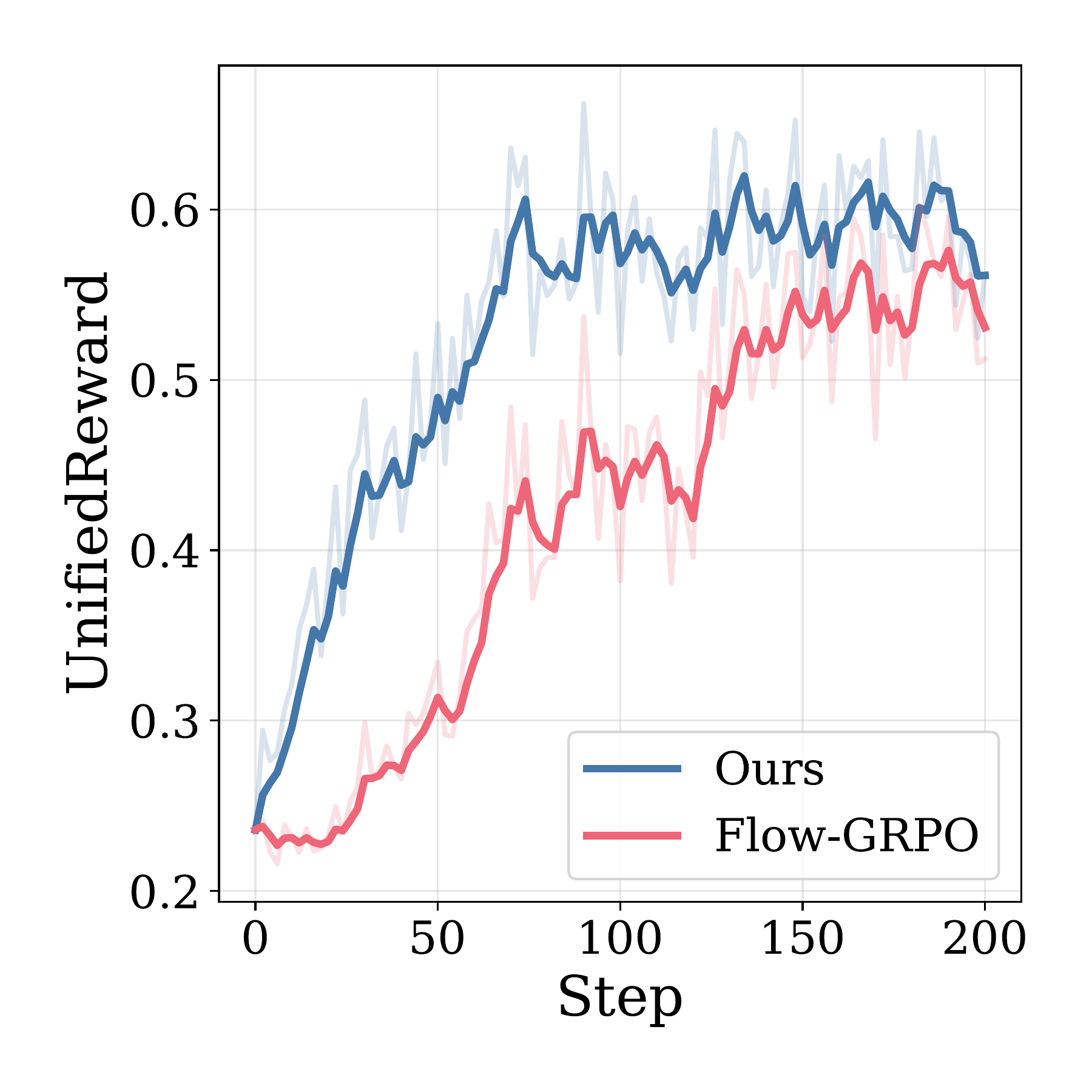
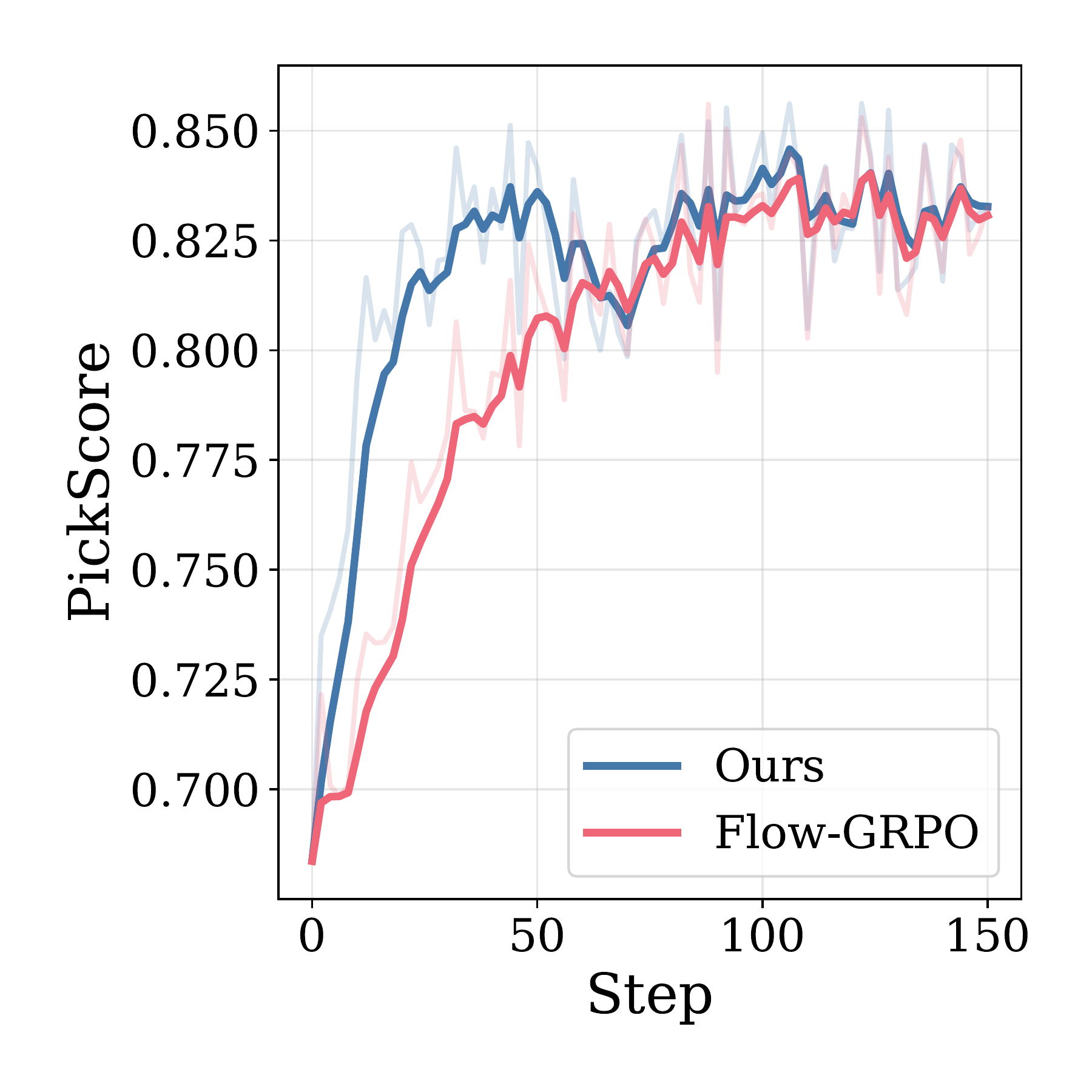
Sample Efficiency
Stepwise-Flow-GRPO consistently outperforms Flow-GRPO in reward per training step across all settings.
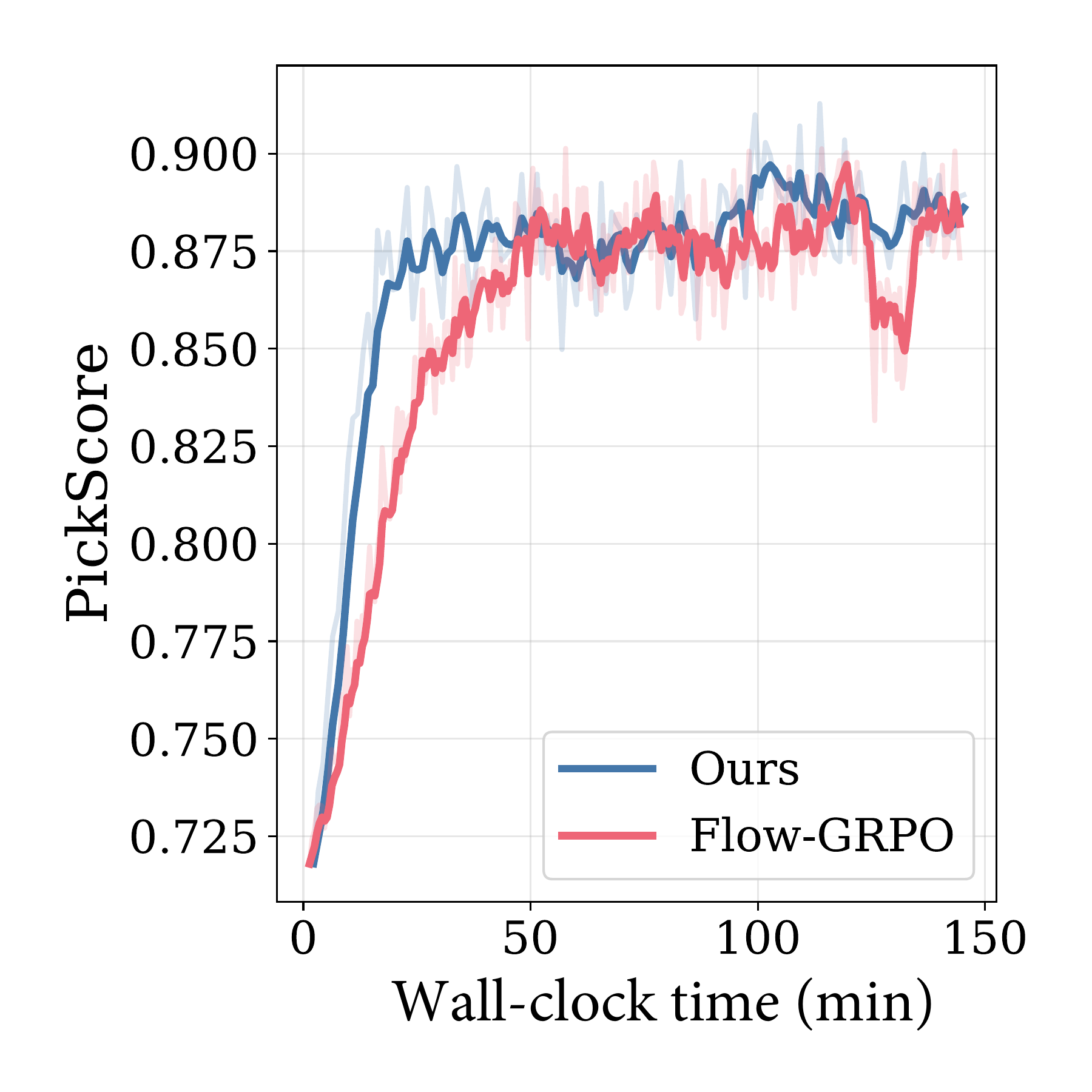
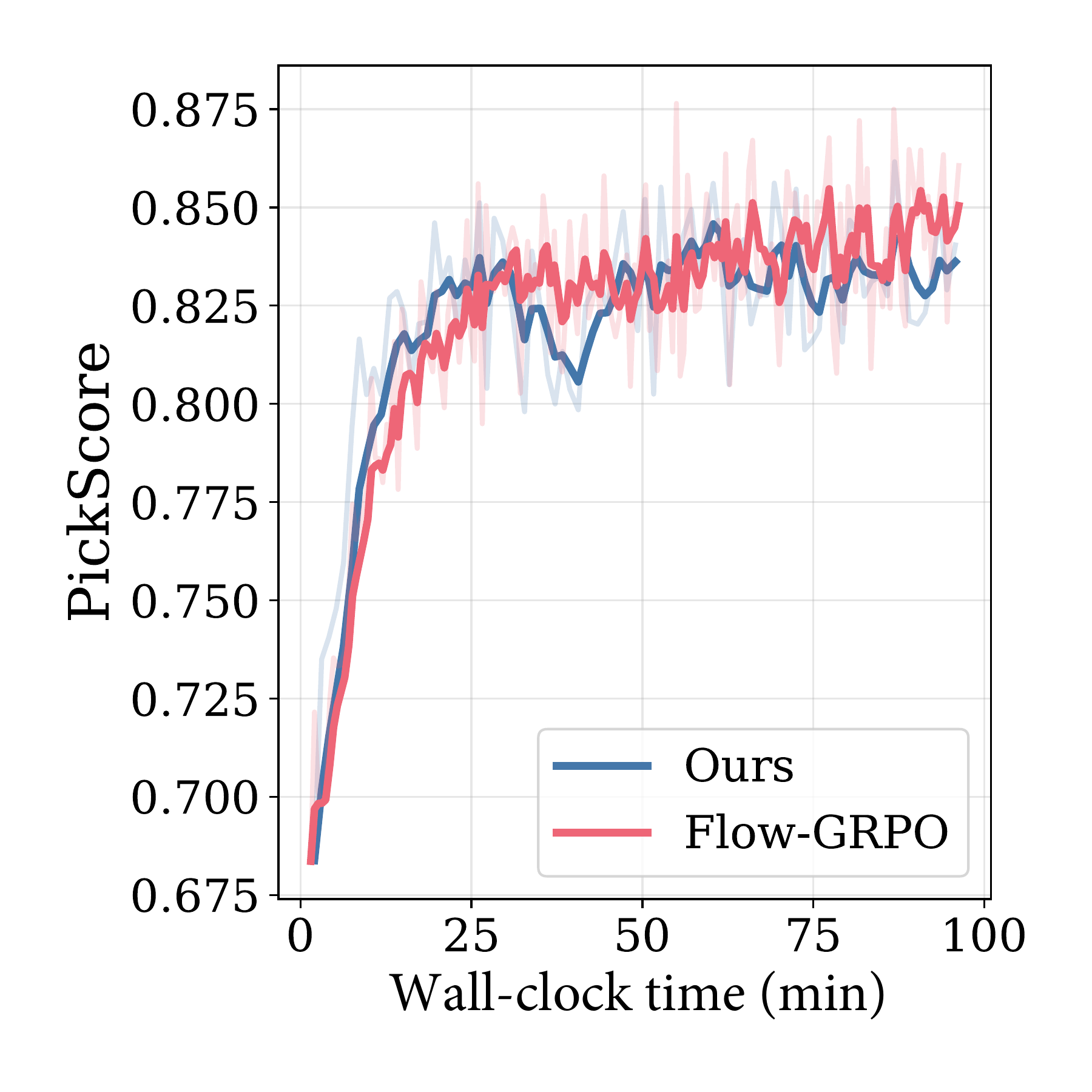
Wall-Clock Efficiency
Despite additional computation for intermediate denoising, our method converges faster in wall-clock time.
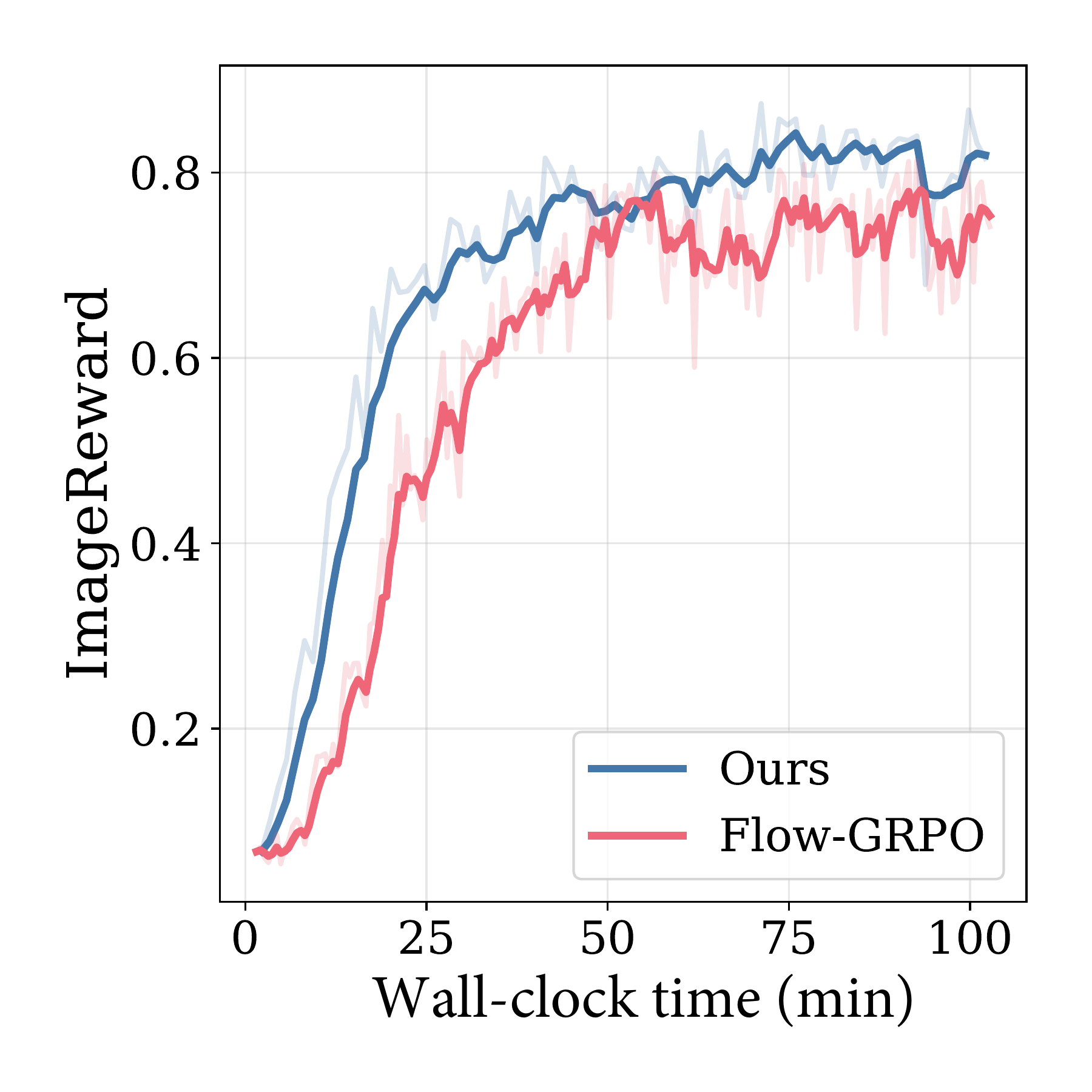
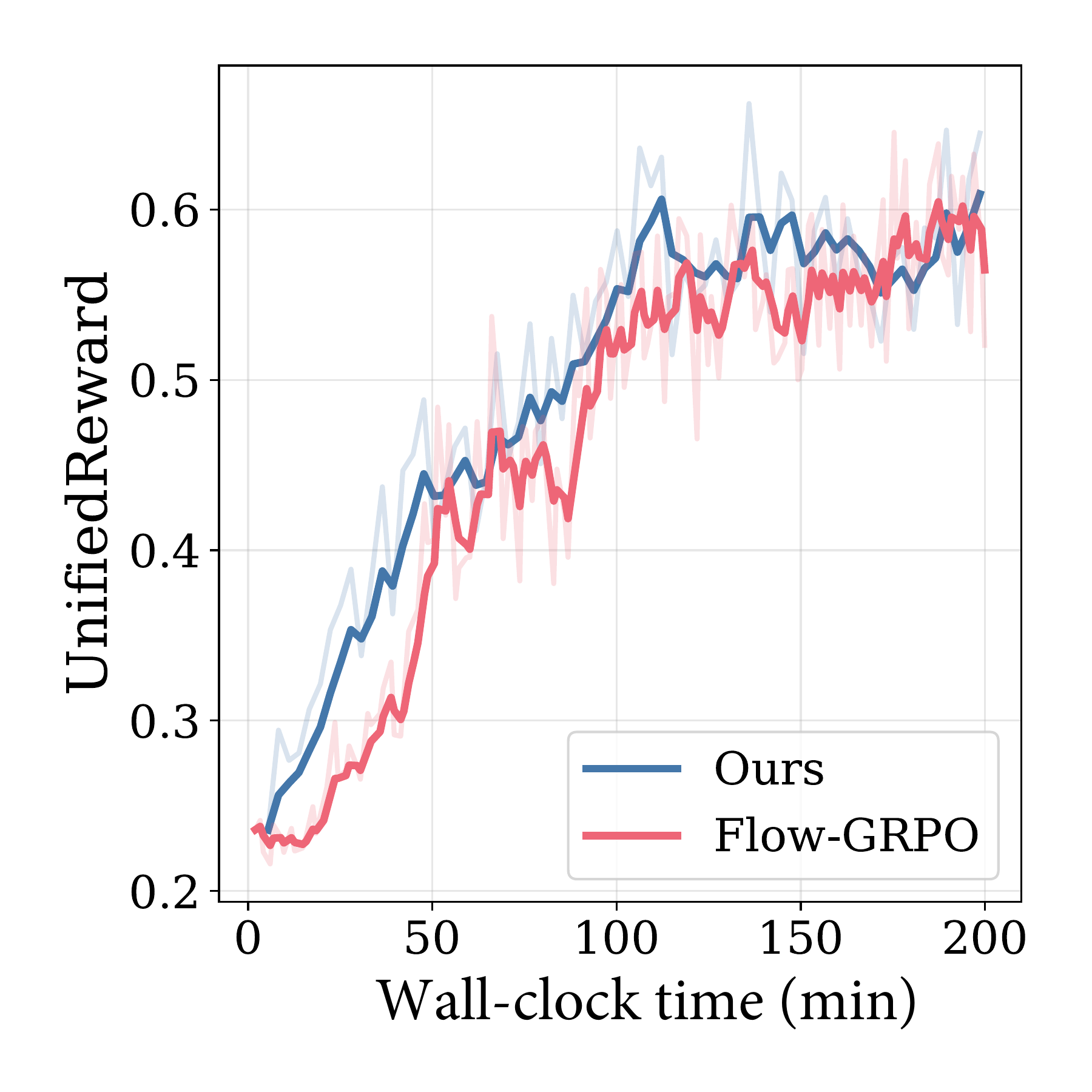
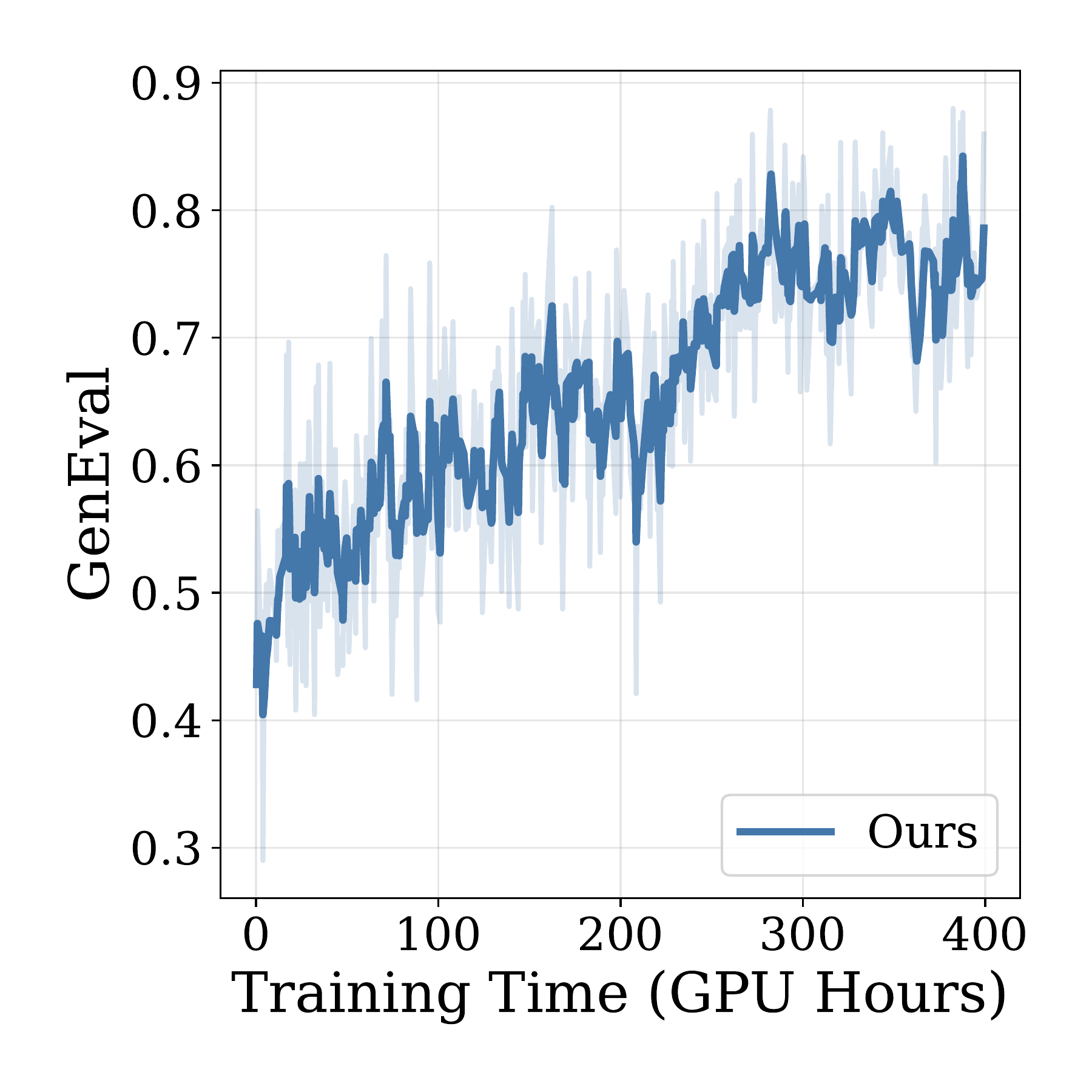
Extended Training
GenEval Benchmark
| Model | Overall | Single Obj. | Two Obj. | Counting | Colors | Position | Attr. Bind. |
|---|---|---|---|---|---|---|---|
| Pretrained Models | |||||||
| SD3.5-M (cfg=1.0) | 0.28 | 0.71 | 0.23 | 0.15 | 0.45 | 0.05 | 0.08 |
| SD3.5-M (cfg=4.5) | 0.63 | 0.98 | 0.78 | 0.50 | 0.81 | 0.24 | 0.52 |
| Standard Training Duration | |||||||
| Flow-GRPO (cfg=1.0, PickScore) | 0.60 | 0.96 | 0.73 | 0.67 | 0.67 | 0.21 | 0.35 |
| Ours (cfg=1.0, PickScore) | 0.60 | 0.96 | 0.75 | 0.67 | 0.67 | 0.21 | 0.34 |
| Flow-GRPO (cfg=4.5, PickScore) | 0.68 | 0.98 | 0.82 | 0.64 | 0.82 | 0.24 | 0.59 |
| Ours (cfg=4.5, PickScore) | 0.71 | 0.98 | 0.85 | 0.70 | 0.82 | 0.29 | 0.59 |
| Extended Training | |||||||
| Flow-GRPO (cfg=4.5, GenEval, 400 GPU hrs) | 0.72 | — | — | — | — | — | — |
| Ours (cfg=4.5, UnifiedReward, 60 GPU hrs) | 0.74 | 0.99 | 0.89 | 0.73 | 0.83 | 0.34 | 0.66 |
| Ours (cfg=4.5, GenEval, 400 GPU hrs) | 0.87 | 0.99 | 0.93 | 0.89 | 0.87 | 0.73 | 0.80 |
| Reference: State-of-the-art Models | |||||||
| Janus-Pro-7B | 0.80 | 0.99 | 0.89 | 0.59 | 0.90 | 0.79 | 0.66 |
| SANA-1.5 4.8B | 0.81 | 0.99 | 0.93 | 0.86 | 0.84 | 0.59 | 0.65 |
| GPT-4o | 0.84 | 0.99 | 0.92 | 0.85 | 0.92 | 0.75 | 0.61 |
Qualitative Results

More Results




BibTeX
@inproceedings{savani2026stepwise,
title = {Stepwise Credit Assignment for GRPO on Flow-Matching Models},
author = {Savani, Yash and Kveton, Branislav and Liu, Yuchen and Wang, Yilin and Shi, Jing and Mukherjee, Subhojyoti and Vlassis, Nikos and Singh, Krishna Kumar},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2026}
}